Histograms are used very often in public health to show the distributions of your independent and dependent variables. Although the basic command for histograms (hist()) in R is simple, getting your histogram to look exactly like you want takes getting to know a few options of the plot. Here I present ways to customize your histogram for your needs.
First, I want to point out that ggplot2 is a package in R that does some amazing graphics, including histograms. I will do a post on ggplot2 in the coming year. However, the hist() function in base R is really easy and fast, and does the job for most of your histogram-ing needs. However, if you want to do complicated histograms, I would recommend reading up on ggplot2.
Okay so for our purposes today, instead of importing data, I'll create some normally distributed data myself. In R, you can generate normal data this way using the rnorm() function:
BMI<-rnorm(n=1000, m=24.2, sd=2.2)
So now we have some BMI data, and the basic histogram plot that comes out of R looks like this:
hist(BMI)
Which is actually pretty nice. There are a number of things that R does by default in creating this histogram, and I think it's useful to print out that information to understand the parameters of this histogram. You can do this by saving the histogram as an object and then printing it like this:
histinfo<-hist(BMI)
histinfo
And you get the output below:

This is helpful because you can see how R has decided to break up your data by default. It shows the breaks, which are the cutoff points for the bins. It shows the counts, intensity/density for each bin (same thing but two different names for R version compatibility), the midpoints of each bin, and then the name of the variable, whether the bins are equidistant, and the class of the object. You can of course take any one of these outputs by itself, i.e. histinfo$counts would give you just the vector of counts.
Now we can manipulate this information to customize our plot.
1. Number of bins
R chooses how to bin your data for you by default using an algorithm, but if you want coarser or finer groups, there are a number of ways to do this. We can see that right now from the output above that the breaks go from 17 to 32 by 1. You can use the breaks() option to change this in a number of ways. An easy way is just to give it one number that gives the number of cells for the histogram:
hist(BMI, breaks=20, main="Breaks=20")
hist(BMI, breaks=5, main="Breaks=5")

The bins don't correspond to exactly the number you put in, because of the way R runs its algorithm to break up the data but it gives you generally what you want. If you want more control over exactly the breakpoints between bins, you can be more precise with the breaks() option and give it a vector of breakpoints, like this:
hist(BMI, breaks=c(17,20,23,26,29,32), main="Breaks is vector of breakpoints")

This dictates exactly the start and end point of each bin. Of course, you could give the breaks vector as a sequence like this to cut down on the messiness of the code:
hist(BMI, breaks=seq(17,32,by=3), main="Breaks is vector of breakpoints")
Note that when giving breakpoints, the default for R is that the histogram cells are right-closed (left open) intervals of the form (a,b]. You can change this with the right=FALSE option, which would change the intervals to be of the form [a,b). This is important if you have a lot of points exactly at the breakpoint.
2. Frequency vs Density
Often, we are more interested in density than frequency, since frequency is relative to your sample size. Instead of counting the number of datapoints per bin, R can give the probability densities using the freq=FALSE option:
hist(BMI, freq=FALSE, main="Density plot")
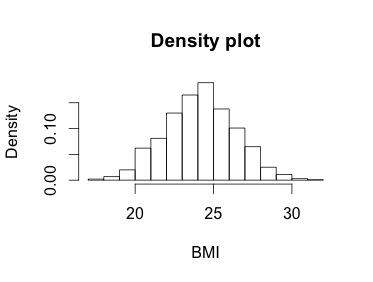
Notice the y-axis now. If the breaks are equidistant, with difference between breaks=1, then the height of each rectangle is proportional to the number of points falling into the cell, and thus the sum of the probability densities adds up to 1. Here I specify plot=FALSE because I just want the histogram output, not the plot, and show how the sum of all of the densities is 1:

However, if you choose to make bins that are not all separated by 1 (like breaks=c(17,25,26, 32) or something like that), then the plot still has an area of 1, but the area of the rectangles is the fraction of data points falling into the cells. The densities are calculated like this as counts/(n*diff(breaks). Thus, this adds up to 1 if add up the areas of the rectangles, i.e. you multiply each density by the difference in the breaks like this:

3. Plot aesthetics
Finally, we can make the histogram better looking by adjusting the x-axis, y-axis, axis labels, title, and color like this:
hist(BMI, freq=FALSE, xlab="Body Mass Index", main="Distribution of Body Mass Index", col="lightgreen", xlim=c(15,35), ylim=c(0, .20))
Here along with our frequency option, I changed the x-axis label, changed the main title, made the color light green, and provided limits for both the x-axis and y-axis. Note that defining the look of you axis using xlim() will not have any impact on the bins - this option is only for the aesthetics of the plot itself.
Finally, I can add a nice normal distribution curve to this plot using the curve() function, in which I specify a normal density function with mean and standard deviation that is equal to the mean and standard deviation of my data, and I add this to my previous plot with a dark blue color and a line width of 2. You can play around with these options to get the kind of line you want:
curve(dnorm(x, mean=mean(BMI), sd=sd(BMI)), add=TRUE, col="darkblue", lwd=2)
And we get this!

Wow, Fantastic Blog, it’s so helpful to me, and your blog is very good, I’ve from your blog here, Keep on going, my friend; I will keep an eye on it,learned a lot.Thanks
ReplyDeleteback pain relief treatment in Hong Kong
Nice! Two things I like especially:
ReplyDelete- saving the result of hist into a variable, to take a look at it. This leads nicely into the things on a histogram that you can change.
- The "curve" function, which I had never heard of before! (This despite using lines, points, text and such all the time.)
This is really an interesting blog as it focuses on the very important topic. i came to know about so many things or tips. Thanks for sharing it...
ReplyDeleteWorking at Heights Training
very good post. i thought you'd need to use the str() command to see the constituent parts of the hist object, so this was interesting. i like the use of curve, although it would be good to know if you can pass arbitrary probability functions as an argument. for example, the pareto distribution is used a lot in insurance where i work,but the density functions are only available from the actuar package, so it would be good to know if you can put something less vanilla than a normal in there. despite this minor observation, i think this is exactly the type of post that takes people one step further. cheers
ReplyDeleteThanks! Yes, you can pass any function into curve - it just evaluates the expression you give it. Or you can also use the density() function, within the lines() function to add to a plot. So for what you want, you could do:
Deletey<-rpareto(1000, shape=100, scale=100)
hist(y, freq=FALSE, ylim=c(0,.75))
lines(density(y), col="red")
Try it and let me know if this helps.
Thanks for the post! I found the way to calculate densities is a bit confusing, my understanding is:
ReplyDeletedensities <- feq/sum(feq)*diff(breaks)
Great post! Thank you so much for sharing..
ReplyDeleteFor those who want to learn R Programming, here is a great new course on youtube for beginners and Data Science aspirants. The content is great and the videos are short and crisp. New ones are getting added, so I suggest to subscribe.
https://www.youtube.com/watch?v=BGWVASxyow8&list=PLFAYD0dt5xCzTQHDhMPZwBoaAXWeVhZzg&index=19