To start, here is a table with all four normal distribution functions and their purpose, syntax, and an example:
| Purpose | Syntax | Example | |
|---|---|---|---|
| rnorm | Generates random numbers from normal distribution |
rnorm(n, mean, sd) | rnorm(1000, 3, .25) Generates 1000 numbers from a normal with mean 3 and sd=.25 |
| dnorm | Probability Density Function (PDF) |
dnorm(x, mean, sd) | dnorm(0, 0, .5) Gives the density (height of the PDF) of the normal with mean=0 and sd=.5. |
| pnorm | Cumulative Distribution Function (CDF) |
pnorm(q, mean, sd) | pnorm(1.96, 0, 1) Gives the area under the standard normal curve to the left of 1.96, i.e. ~0.975 |
| qnorm | Quantile Function - inverse of pnorm |
qnorm(p, mean, sd) | qnorm(0.975, 0, 1) Gives the value at which the CDF of the standard normal is .975, i.e. ~1.96 |
Note that for all functions, leaving out the mean and standard deviation would result in default values of mean=0 and sd=1, a standard normal distribution.
Another important note for the pnorn() function is the ability to get the right hand probability using the lower.tail=FALSE option. For example,

In the first line, we are calculating the area to the left of 1.96, while in the second line we are calculating the area to the right of 1.96.
With these functions, I can do some fun plotting. I create a sequence of values from -4 to 4, and then calculate both the standard normal PDF and the CDF of each of those values. I also generate 1000 random draws from the standard normal distribution. I then plot these next to each other. Whenever you use probability functions, you should, as a habit, remember to set the seed. Setting the seed means locking in the sequence of "random" (they are pseudorandom) numbers that R gives you, so you can reproduce your work later on.
set.seed(3000) xseq<-seq(-4,4,.01) densities<-dnorm(xseq, 0,1) cumulative<-pnorm(xseq, 0, 1) randomdeviates<-rnorm(1000,0,1) par(mfrow=c(1,3), mar=c(3,4,4,2))
plot(xseq, densities, col="darkgreen",xlab="", ylab="Density", type="l",lwd=2, cex=2, main="PDF of Standard Normal", cex.axis=.8)
plot(xseq, cumulative, col="darkorange", xlab="", ylab="Cumulative Probability",type="l",lwd=2, cex=2, main="CDF of Standard Normal", cex.axis=.8)
hist(randomdeviates, main="Random draws from Std Normal", cex.axis=.8, xlim=c(-4,4))
The par() parameters set up a plotting area of 1 row and 3 columns (mfrow), and move the three plots closer to each other (mar). Here is a good explanation of the plotting area. The output is below:

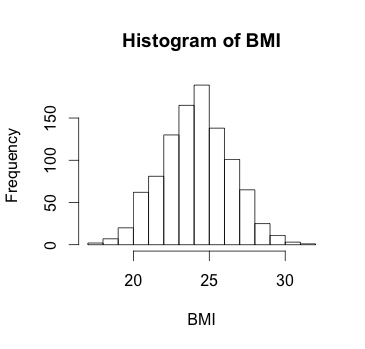
Now, when we have our actual data, we can do a visual check of the normality of our outcome variable, which, if we assume a linear relationship with normally distributed errors, should also be normal. Let's make up some data, where I add noise by using rnorm() - here I'm generating the same amount of random numbers as is the length of the xseq vector, with a mean of 0 and a standard deviation of 5.5.
xseq<-seq(-4,4,.01)
y<-2*xseq + rnorm(length(xseq),0,5.5)
And now I can plot a histogram of y (check out my post on histograms if you want more detail) and add a curve() function to the plot using the mean and standard deviation of y as the parameters:
Here, the curve() function takes as its first parameter a function itself (or an expression) that must be written as some function of x. Our function here is dnorm(). The x in the dnorm() function is not an object we have created; rather, it's indicating that there's a variable that is being evaluated, and the evaluation is the normal density at the mean of y and standard deviation of y. Make sure to include add=TRUE so that the curve is plotted on the same plot as the histogram. Here is what we get:

Here are some other good sources on the topic of probability distribution functions: